In the last few months, I’ve posted quite a few articles showing demos in Snowflake. My personal goal was to post one article per week covering a single topic in Snowflake, SQL Server or technical leadership. I accomplished that goal by spending the early morning hours before my family woke up by reading, testing and applying the skills I’ve learned this year to craft articles that I found helpful to myself, but also hoped that others would find useful.
Since some of my demos all build upon one another, and posting the full set of code for each article can make them difficult to read at times, I’ve created a public GitHub repository where I’ll post the code for my demos. I will continue to add to the repo as I find new and cool things to discuss and try out with Snowflake, Streamlit, or Python for data engineering, and I hope others find it useful as well!
In my last article, I showed how to create a simple bar chart in a Native Streamlit app in Snowflake. It works great for simple bar charts. What if I wanted to see the breakdown of parts sales by manufacturer by country/region from the previous example? A stacked bar chart with each manufacturer having a different color would be ideal, and according to the st.bar_chart documentation the “color” parameter should do this nicely; however, the “color” parameter isn’t supported in a native Streamlit app yet (as of the writing of this article).
Looking more closely at the st.bar_chart documentation a little more closely, I saw the following:
This is syntax-sugar around st.altair_chart. The main difference is this command uses the data’s own column and indices to figure out the chart’s spec. As a result this is easier to use for many “just plot this” scenarios, while being less customizable.
If st.bar_chart does not guess the data specification correctly, try specifying your desired chart using st.altair_chart.
So, st.bar_chart is just a slick wrapper for st.altair_chart, which opens up a world of options for the charts – and can handle the specifics of the stacked bar chart I wanted to see. Be sure to import the Altair library in the Steamlit app code.
#IMPORT STREAMLIT LIBRARY
import streamlit as st
#IMPORT SNOWPARK SESSION
from snowflake.snowpark.context import get_active_session
#IMPORT PANDAS
import pandas as pd
#IMPORT ALTAIR
import altair as alt
Update the Data View
First, I’ll need to update my underlying view in the STREAMLIT_DATA schema to include the manufacturer of the part for the orders by year, country, and region. Additionally, I’ll need to adjust my grouping sets to ensure the proper groups are being calculated for the charts. To get the manufacturer’s name, I had to add the LINEITEM and PART tables to the query; adding the appropriate columns and groups as needed.
CREATE OR REPLACE VIEW VW_SALES_DATA AS
SELECT
YEAR(O.O_ORDERDATE) AS ORDER_YEAR,
R.R_NAME AS REGION_NAME,
N.N_NAME AS COUNTRY_NAME,
P.P_MFGR AS PART_MFG,
SUM(L.L_EXTENDEDPRICE) AS TOTAL_SALES
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS as o
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER AS c
ON
o.O_CUSTKEY = c.C_CUSTKEY
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.NATION as N
ON
C.C_NATIONKEY = N.N_NATIONKEY
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.REGION as R
ON
N.N_REGIONKEY=R.R_REGIONKEY
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM AS L
ON
O.O_ORDERKEY = L.L_ORDERKEY
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.PART AS P
ON
L.L_PARTKEY = P.P_PARTKEY
GROUP BY
GROUPING SETS(
(YEAR(O.O_ORDERDATE),R.R_NAME,N_NAME,P.P_MFGR),
(YEAR(O.O_ORDERDATE),R.R_NAME,P.P_MFGR)
);
Update Streamlit Data Frames
With the underlying data view updated as needed, I’ll need to update the data frames in the Steamlit app to include the new column for the manufacturer. In MY_FIRST_STREAMLIT.py, I’ll add “PART_MFG” to the query and then add “PART_MFG” to the pandas data frame.
#STEP 1: BUILD SQL - SALES IN MILLIONS BY YEAR,INCLUDE AN INDEX COLUMN FOR CHART BUILDING
sql_bar_chart = f"""
SELECT
ROW_NUMBER() OVER (ORDER BY ORDER_YEAR) AS DF_IDX,
ORDER_YEAR,
PART_MFG,
ROUND((TOTAL_SALES / 1000000),3)::NUMERIC(19,3) as SALES_IN_MILLIONS
FROM
STREAMLIT_DATA.VW_SALES_DATA
WHERE
REGION_NAME = '{region_name}'
AND
COALESCE(COUNTRY_NAME,'ALL')='{country_name}'
ORDER BY
DF_IDX
"""
#STEP 2: COLLECT THE DATAFRAME
bar_chart_df = session.sql(sql_bar_chart).collect()
#STEP 3: CONVERT TO A PANDAS DATAFRAME
### ORIGINAL DATAFRAME ###
#bar_pandas_df = pd.DataFrame(bar_chart_df,columns=["DF_IDX","ORDER_YEAR","SALES_IN_MILLIONS"]).set_index("DF_IDX")
### UPDATED DATA FRAME###
bar_pandas_df = pd.DataFrame(bar_chart_df,columns=["DF_IDX","ORDER_YEAR","PART_MFG","SALES_IN_MILLIONS"]).set_index("DF_IDX")
#STEP 4: CONVERT TO PROPER DATATYPES
### ORIGINAL ###
#bar_pandas_df = bar_pandas_df.astype({"ORDER_YEAR": "object","SALES_IN_MILLIONS":"float"})
### UPDATED ###
bar_pandas_df = bar_pandas_df.astype({"ORDER_YEAR": "object","SALES_IN_MILLIONS":"float","PART_MFG":"object"})
Stacked Bar Chart with Altair Chart
Using st.altair_chart to build the stacked bar chart is a relatively easy conversion given that most of the work for this example is done in Snowflake SQL and the Pandas data frame already. The st.altair_chart has a lot more customization that can be applied for each element – for example, setting the axis titles or setting a specific range on the axis scale. Both Streamlit and Altair have good documentation on all the options available.
Building the Chart
Unlike using st.bar_chart, I had to first build a chart object to use st.altair_chart. Inside the chart object is where I specified things like the data frame to use, the x and y-axis data and labels as well as which column determined the color.
#CREATE THE ALTAIR CHART DATA
chart = alt.Chart(bar_pandas_df).mark_bar().encode(
x = alt.X("ORDER_YEAR",title="ORDER YEAR",type="nominal")
,y=alt.Y("SALES_IN_MILLIONS",title="SALES IN MILLIONS")
,color= alt.Color("PART_MFG",title="PARTS MANUFACTURER")
)
st.altair_chart(chart,use_container_width=True,theme="streamlit")
In the code block above, each element of the chart is specified with a function call from the Altair library. Each element has good documentation on the Altair site to further explain all the options. After building the chart object, I added the object to my app with st.altair_chart. Notice, I set the chart to use its container width to fill the column as well as set the theme to “streamlit”. By setting the theme option to Streamlit, the “look and feel” of the chart matches other elements of a Streamlit app. Otherwise, the theme would default to the Altair settings.
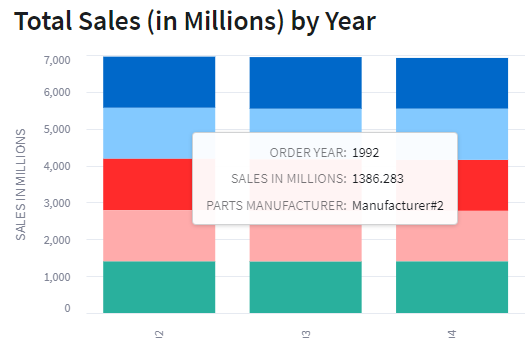
Sales Data with Stacked Bar Chart
Running the app now shows the sales data with a stacked bar chart with different colors representing each manufacturer in the overall total. Hovering over one of the bar colors will show a pop-up of the data point being plotted.
Hover-over Bar Chart Data Point
Conclusion
Plotting a chart in a Native Streamlit app in Snowflake can be a very effective way to visualize your data for consumption. Some of the more simple options like st.bar_chart do a good job with simple data, but to harness the power of some more complicated charts, look to st.altair_chart as there are a lot more chart types available and the configurations options are much more detailed.
So far in this series showing the capabilities of native Streamlit apps in Snowflake, I’ve created an app to display “Hello, world!”, connected to Snowflake to show session info and return query results in a data frame. Now I’ll add some additional functionality to format my app layout in columns and add two selection boxes to add filters to some sample data.
Creating Sample Data
When creating a trial Snowflake account Snowflake provides some sample data to “play” with and test the capabilities of Snowflake. I’ll use the provided sample data to create a view for my app. To keep things tidy, I’ll also create a new schema for my Streamlit data and then create a view in that schema to show annual sales (in millions of dollars) per country per region from the sample data.
STREAMLIT_DATA Schema Setup
First, I’ll need to set up my new schema and grant usage on that schema to the role that runs the app, ST_DEMO_ROLE.
USE DATABASE STREAMLIT_DB;
CREATE SCHEMA STREAMLIT_DATA;
GRANT USAGE ON SCHEMA STREAMLIT_DATA TO ROLE ST_DEMO_ROLE;
VW_SALES_DATA View Setup
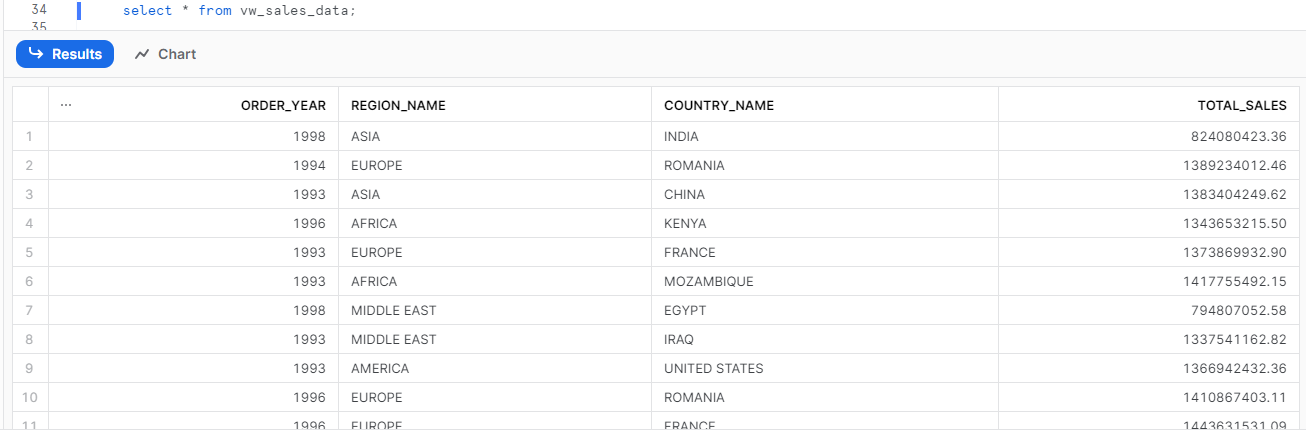
Next, I’ll use some of the Snowflake sample data to create a view to summarize the sales data by year by region, and country. I use grouping sets to a total, or “ALL” countries value.
USE SCHEMA STREAMLIT_DB.STREAMLIT_DATA;
CREATE OR REPLACE VIEW VW_SALES_DATA AS
SELECT
YEAR(O.O_ORDERDATE) AS ORDER_YEAR,
R.R_NAME AS REGION_NAME,
N.N_NAME AS COUNTRY_NAME,
SUM(O.O_TOTALPRICE) AS TOTAL_SALES
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS as o
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER AS c
ON
o.O_CUSTKEY = c.C_CUSTKEY
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.NATION as N
ON
C.C_NATIONKEY = N.N_NATIONKEY
JOIN
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.REGION as R
ON
N.N_REGIONKEY=R.R_REGIONKEY
GROUP BY
GROUPING SETS(
(YEAR(O.O_ORDERDATE),R.R_NAME,N_NAME),
(YEAR(O.O_ORDERDATE),R.R_NAME)
);
Sample Data View Output
Using Column Layouts
Streamlit provides several formatting options as standard functions, one of which is columns that can be set up by using st.columns(). By using st.columns, I can define co1 and col2 as variables and then reference those in my Python script to add additional Streamlit objects to them. In this case, I’ll add one selection box to each column – one on the left for a region selector, and one on the right for a country selector. The values for each selection box will come from the VW_SALES_DATA view. Additionally, the country selection box will be filtered based on the selection of the region box through the use of the Python string formatting.
Data Selection Boxes
In the code block below, I use st.columns to define my two columns, and then using “with” syntax, I define the SQL, data frame, and select box for each column. In the country column, I use the region_name variable from the first select box to update my WHERE clause in the country SQL statement (see highlighted lines).
#ADD SOME COLUMNS FOR SELECTION BOXES
col1,col2 = st.columns(2)
#COL1 = REGION
with col1:
region_sql ="""
SELECT
REGION_NAME
FROM
STREAMLIT_DATA.VW_SALES_DATA
GROUP BY
REGION_NAME
ORDER BY
REGION_NAME;
"""
region_df = session.sql(region_sql).collect()
region_name = st.selectbox("Choose a region:",options=region_df)
#COL2 = COUNTRY
with col2:
country_sql=f"""
SELECT
COALESCE(COUNTRY_NAME,'ALL') AS ST_COUNTRY_NAME
FROM
STREAMLIT_DATA.VW_SALES_DATA
WHERE
REGION_NAME = '{region_name}'
GROUP BY
COUNTRY_NAME
ORDER BY
COUNTRY_NAME ASC NULLS FIRST;
"""
country_df = session.sql(country_sql).collect()
country_name = st.selectbox("Choose a country:",options=country_df)
Updated layout using st.columns()
Customizing st.columns()
In the code above, st.columns() generates two columns of equal width in the app; however, I can also specify the relative width of each column to one another. In the code block below, I create two new column variables prefixed with “r2” to indicate row 2 of the app and specify that the relative width of column 2 is four times the width of column 1. For additional information on column setup, please see the Streamlit documentation.
r2col1,r2col2 = st.columns([1,4])
Bar Chart Data Setup
To display a bar chart as well as a data frame to show the underlying data, I’ll first need to query the VW_SALES_DATA view and apply the filters specified in the region and country select boxes. In the query, I am adding a row_number for the data index as well as converting the sales numbers into millions of dollars – primarily to keep the numbers smaller for screen output.
In step three of the code block below, I am converting the Snowpark data frame to a Pandas data frame, setting the index as well, and defining the column names. This step is done to help simplify the bar chart creation. I found during testing that the native Snowpark data frame would work, but calling the columns by name in the axis labels caused some odd behavior. Pandas worked better for the demo. Speaking of Pandas, I also added an import for Pandas at the top of my app.
#IMPORT STREAMLIT LIBRARY
import streamlit as st
#IMPORT SNOWPARK SESSION
from snowflake.snowpark.context import get_active_session
#IMPORT PANDAS
import pandas as pd
I also introduce some additional data type conversion methods for Pandas data frames as part of this code. While not 100% necessary, I did so to force the data values to what I wanted them to be for display on the charts.
#BUILD A BAR CHART
#STEP 1: BUILD SQL - SALES IN MILLIONS BY YEAR,INCLUDE AN INDEX COLUMN FOR CHART BUILDING
sql_bar_chart = f"""
SELECT
ROW_NUMBER() OVER (ORDER BY ORDER_YEAR) AS DF_IDX,
ORDER_YEAR,
ROUND((TOTAL_SALES / 1000000),3)::NUMERIC(19,3) as SALES_IN_MILLIONS
FROM
STREAMLIT_DATA.VW_SALES_DATA
WHERE
REGION_NAME = '{region_name}'
AND
COALESCE(COUNTRY_NAME,'ALL')='{country_name}'
ORDER BY
DF_IDX
"""
#STEP 2: COLLECT THE DATAFRAME
bar_chart_df = session.sql(sql_bar_chart).collect()
#STEP 3: CONVERT TO A PANDAS DATAFRAME
bar_pandas_df = pd.DataFrame(bar_chart_df,columns=["DF_IDX","ORDER_YEAR","SALES_IN_MILLIONS"]).set_index("DF_IDX")
#STEP 4: CONVERT TO PROPER DATATYPES
bar_pandas_df = bar_pandas_df.astype({"ORDER_YEAR": "object","SALES_IN_MILLIONS":"float"})
Display the Chart Data Frame
In the first column, I want to display the underlying data for my chart. As I’ve shown in a previous post, displaying a data frame or data grid in Streamlit is just a couple of lines of code:
with r2col1:
#STEP 6: SHOW UNDERLYING DATA
st.subheader("Underlying Chart Data")
st.dataframe(data=bar_pandas_df)
Display the Bar Chart
Just like most other things in Streamlit, adding a bar chart is pretty straightforward and only needs a single function st.bar_chart(). For this example, I’ll set the year on the x-axis and the sales in millions on the y-axis. In the Streamlit documentation, st.bar_chart() also supports a “color” parameter to set the color palette of the chart. As of this writing, the color parameter is not supported in native Streamlit apps in Snowflake.
with r2col2:
#STEP 5: CREATE THE CHART
st.subheader("Total Sales (in Millions) by Year")
st.bar_chart(data=bar_pandas_df,x="ORDER_YEAR",y="SALES_IN_MILLIONS")
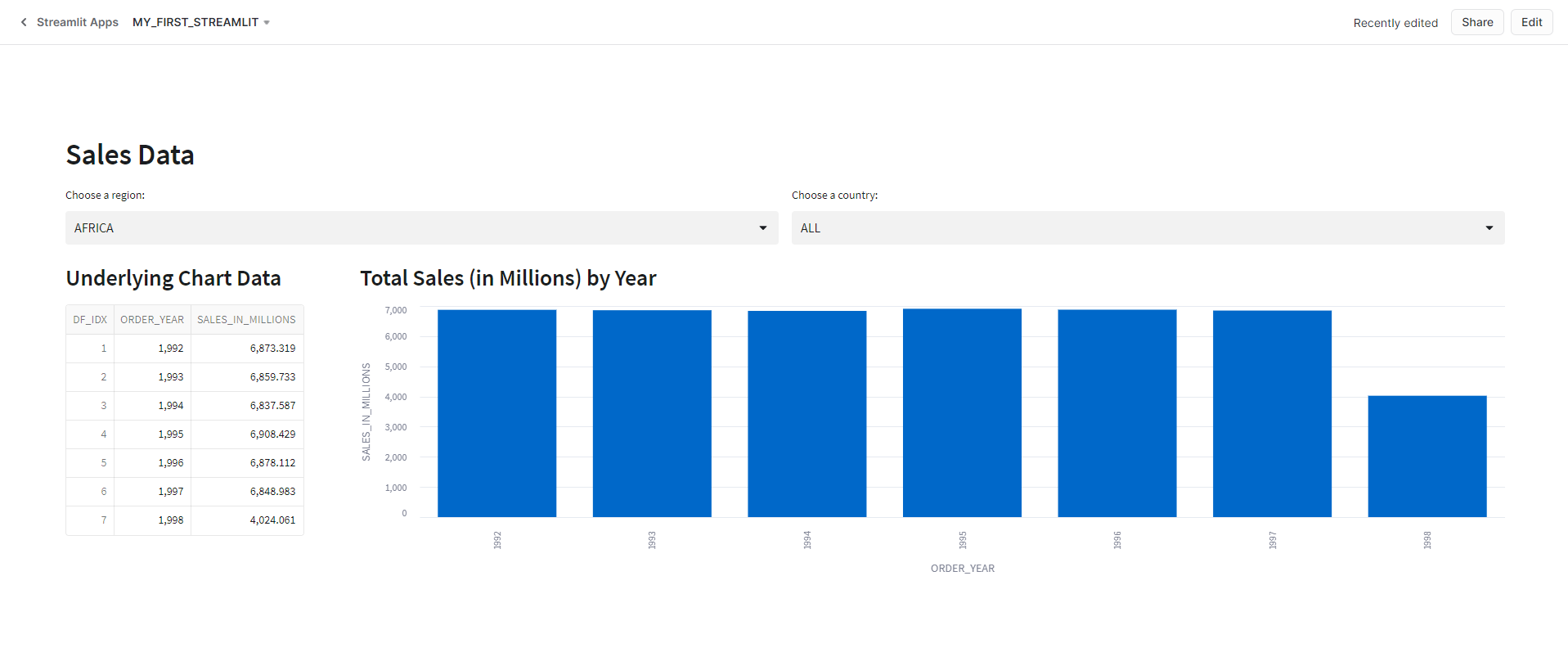
Final App Presentation
Now that I’ve added all the code, I can run my app and see how it lays out on the screen.
Final App in Use
As I change the selected values in the select boxes, the app queries the data, displays it to the screen in the data frame, and updates the bar chart. Behind the scenes, with each change, the app is re-running, so each change executes the proper SQL commands against Snowflake. In other non-native Streamlit apps, I could use st.cache to load the underlying data into data frames first and add them to our app cache. From there, the changes to the select boxes would then filter the data frames loaded in the cache to update the app. At this time st.cache is unsupported in native Streamlit apps in Snowflake. For a full list of unsupported features, see the Snowflake Documentation.
Wrapping Up
In this article, I walked through creating a simple bar chart from some of the sample Snowflake Data provided with a trial account. The demo shows just how easy it is to make an app in Snowflake with Streamlit. There are still some limitations to the native apps, but it wouldn’t surprise me if many of the unsupported features become supported features soon.