
A few weeks ago, I wrote about polymorphism in Snowflake as a way to “get around” the issue with Snowflake procedures not allowing default parameter values. As the Snowflake platform evolves, more features are constantly being added – today I discovered that default parameter values are supported in procedures!
Prior Example Review
In the previous example, I provided a stored procedure that writes to an event log table in Snowflake with two input parameters and a second version of the procedure that used polymorphism to only use one parameter. The original code is below:
/*CREATE PROC*/
CREATE OR REPLACE PROCEDURE USP_EVT_LOG(EVT_TYPE VARCHAR(10),EVT_DESC VARCHAR(1000))
RETURNS BOOLEAN
AS
BEGIN
INSERT INTO TBL_EVT_LOG(EVT_TYPE,EVT_DESC)
VALUES(COALESCE(:EVT_TYPE,'INFO'),:EVT_DESC);
RETURN TRUE;
END;
/*CREATE ALTERNATE SIGNATURE*/
CREATE OR REPLACE PROCEDURE USP_EVT_LOG(EVT_DESC VARCHAR(1000))
RETURNS BOOLEAN
AS
DECLARE
RETURN_VALUE BOOLEAN DEFAULT FALSE;
BEGIN
RETURN_VALUE := (CALL USP_EVT_LOG('INFO',:EVT_DESC));
RETURN RETURN_VALUE;
END;
Using Default Parameters
Now that Snowflake can utilize default parameters for stored procedures, I can re-write the procedure to set the EVT_TYPE parameter default to NULL, or any other value, if not specified in the procedure call.
Parameter Order
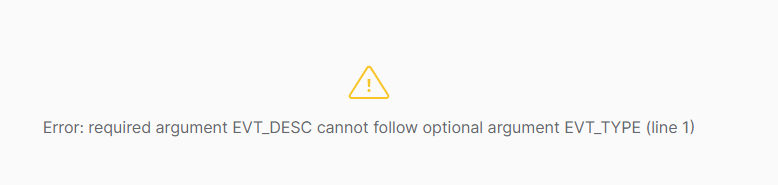
One difference from SQL Server is that the parameter order matters in Snowflake when using defaults in the procedure definition. Required parameters must appear in the signature before any optional parameters. For example, if I leave the parameters in the same order as before, but set EVT_TYPE to have a default, Snowflake will throw an error.
CREATE OR REPLACE PROCEDURE ST_DEMO_DB.RAW_DATA.USP_EVT_LOG("EVT_TYPE" VARCHAR(10) DEFAULT NULL, "EVT_DESC" VARCHAR(1000))
RETURNS BOOLEAN
LANGUAGE SQL
EXECUTE AS OWNER
AS
$$
BEGIN
INSERT INTO TBL_EVT_LOG(EVT_TYPE,EVT_DESC)
VALUES(COALESCE(:EVT_TYPE,'INFO'),:EVT_DESC);
RETURN TRUE;
END
$$;
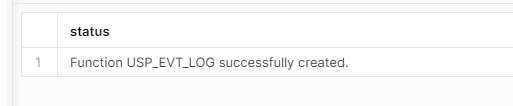
Since I want the EVT_TYPE to be optional, I’ll have to swap the order of the input parameters in the signature to ensure the desired functionality.
CREATE OR REPLACE PROCEDURE ST_DEMO_DB.RAW_DATA.USP_EVT_LOG("EVT_DESC" VARCHAR(1000),"EVT_TYPE" VARCHAR(10) DEFAULT NULL)
RETURNS BOOLEAN
LANGUAGE SQL
EXECUTE AS OWNER
AS
$$
BEGIN
INSERT INTO TBL_EVT_LOG(EVT_TYPE,EVT_DESC)
VALUES(COALESCE(:EVT_TYPE,'INFO'),:EVT_DESC);
RETURN TRUE;
END
$$;
Executing the Procedure
With the parameter set to have a default value now, there are several ways to appropriately call the procedure to get the desired function. Each of the following options will properly call the USP_EVT_LOG procedure and write a record to TBL_EVT_LOG:
/*ONLY PASS REQUIRED STRING*/
CALL USP_EVT_LOG('Sample event log;unnamed parameters');
/*PASS REQUIRED STRING BY NAME*/
CALL USP_EVT_LOG(EVT_DESC =>'Sample event log;named parameters');
/*PASS VALUES FOR BOTH PARAMETERS*/
CALL USP_EVT_LOG(EVT_DESC =>'Sample event lot;named parameters including value for optional',EVT_TYPE=> 'INFO');
/*PARAMETER ORDER DOES NOT MATTER IF BOTH SPECIFIED BY NAME*/
CALL USP_EVT_LOG(EVT_TYPE=> 'INFO',EVT_DESC =>'Sample event lot;named parameters including value for optional;params in opposite order');

Conclusion
Adding the ability to set default parameter values for procedures reduces the need for the overuse of polymorphism with multiple signatures just to account for default parameter values. Polymorphism is still supported in Snowflake and still has a place in design practices.
Kudos to Snowflake for adding this feature!








